
California State University, San Marcos
I work at alwaysAI as a ML engineer. Recently, I developed a Bring Your Own Architecture (BYOA) software with my team at alwaysAI. Previously, I defended by PhD dissertation in Computer Science at Temple University , Philadelphia. During my PhD, I was advised by Dr. Longin Jan Latecki. My disserttation primarily focuses on building computer vision algorithms for analyzing handwritten documents. Our work has developed a word detection algorithm for camera-captured handwritten images. We also build the strokes trajectory recovery algorithm for full-page unconstraint handwritten documents. Finally, we proposed a state-of-the-art diffusion model with multiscale attention features.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Temple University, PhiladelphiaPh.D. Computer and information ScienceAug 2017 - Dec 2023
Temple University, PhiladelphiaPh.D. Computer and information ScienceAug 2017 - Dec 2023 -
 University of Engineering and Technology, LahoreB.S. Electrical EngineeringAug 2008 - May 2012
University of Engineering and Technology, LahoreB.S. Electrical EngineeringAug 2008 - May 2012
News
Selected Publications (view all )
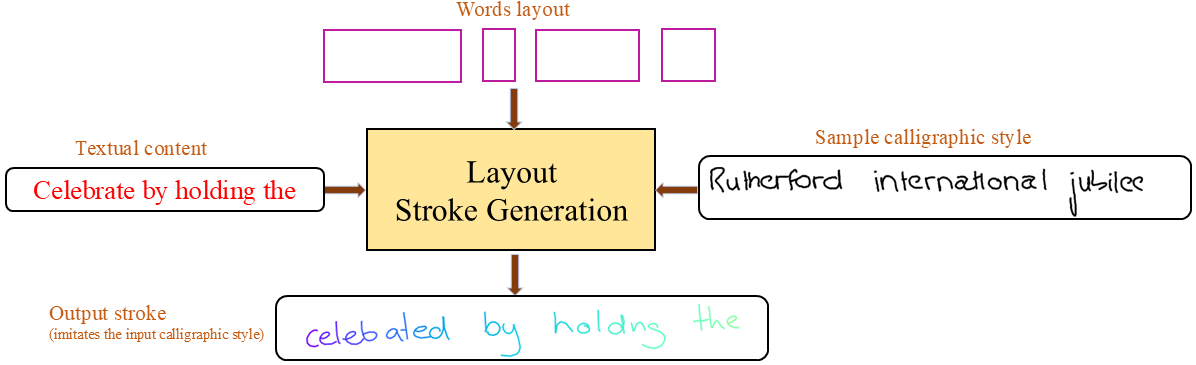
Layout Stroke Imitation: A Layout Guided Handwriting Stroke Generation for Style Imitation with Diffusion Model
Sidra Hanif, Longin Jan Latecki
arxiv 2025
Handwriting stroke generation is crucial for improving the performance of tasks such as handwriting recognition and writer’s order recovery. In handwriting stroke generation, it is significantly important to imitate the sample calligraphic style. The previous studies have suggested utilizing the calligraphic features of the handwriting. However, they had not considered word spacing (word layout) as an explicit handwriting feature, which results in inconsistent word spacing for style imitation. Firstly, this work proposes multi-scale attention features for calligraphic style imitation. These multi-scale feature embeddings highlight the local and global style features. Secondly, we propose to include the words layout, which facilitates word spacing for handwriting stroke generation. Moreover, we propose a conditional diffusion model to predict strokes in contrast to previous work, which directly generated style images. Stroke generation provides additional temporal coordinate information, which is lacking in image generation. Hence, our proposed conditional diffusion model for stroke generation is guided by calligraphic style and word layout for better handwriting imitation and stroke generation in a calligraphic style. Our experimentation shows that the proposed diffusion model outperforms the current state-of-the-art stroke generation and is competitive with recent image generation networks.
Layout Stroke Imitation: A Layout Guided Handwriting Stroke Generation for Style Imitation with Diffusion Model
Sidra Hanif, Longin Jan Latecki
arxiv 2025
Handwriting stroke generation is crucial for improving the performance of tasks such as handwriting recognition and writer’s order recovery. In handwriting stroke generation, it is significantly important to imitate the sample calligraphic style. The previous studies have suggested utilizing the calligraphic features of the handwriting. However, they had not considered word spacing (word layout) as an explicit handwriting feature, which results in inconsistent word spacing for style imitation. Firstly, this work proposes multi-scale attention features for calligraphic style imitation. These multi-scale feature embeddings highlight the local and global style features. Secondly, we propose to include the words layout, which facilitates word spacing for handwriting stroke generation. Moreover, we propose a conditional diffusion model to predict strokes in contrast to previous work, which directly generated style images. Stroke generation provides additional temporal coordinate information, which is lacking in image generation. Hence, our proposed conditional diffusion model for stroke generation is guided by calligraphic style and word layout for better handwriting imitation and stroke generation in a calligraphic style. Our experimentation shows that the proposed diffusion model outperforms the current state-of-the-art stroke generation and is competitive with recent image generation networks.

A Comprehensive Framework for Stroke Trajectory Recovery for Unconstrained Handwritten Documents
Sidra Hanif
PhD dissertation 2024
A Comprehensive Framework for Stroke Trajectory Recovery for Unconstrained Handwritten Documents
Sidra Hanif
PhD dissertation 2024
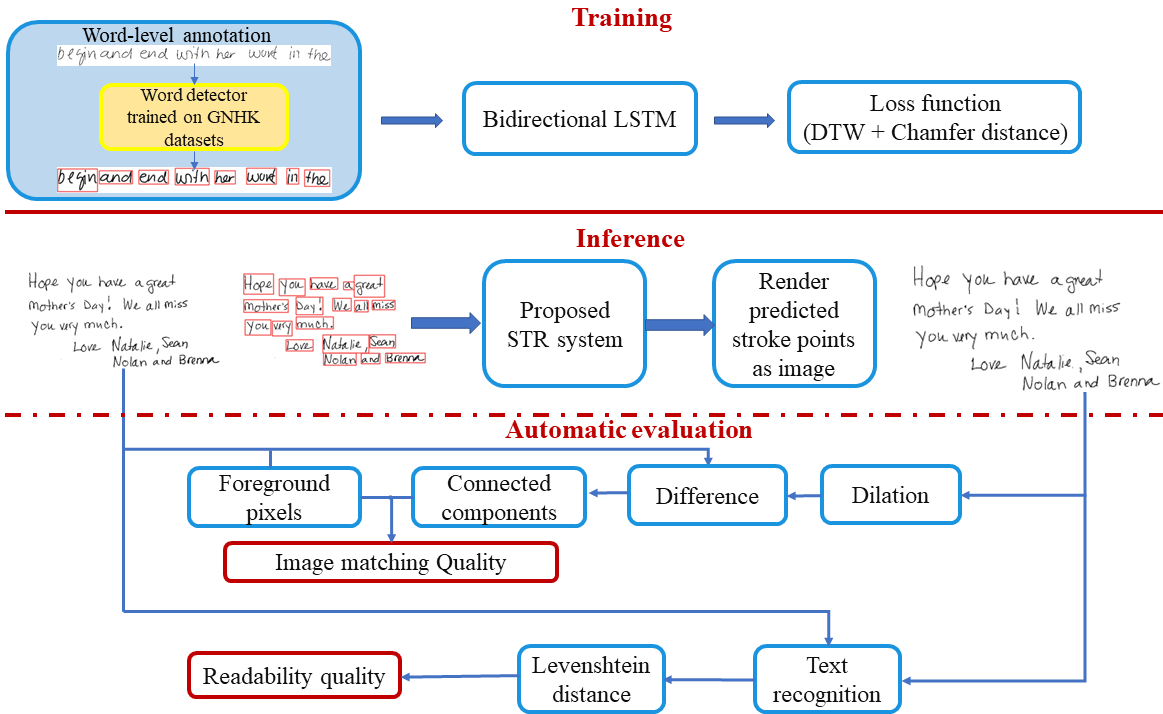
Strokes Trajectory Recovery for Unconstrained Handwritten Documents with Automatic Evaluation.
Sidra Hanif, Longin Jan Latecki
International Conference on Pattern Recognition Applications and Methods (ICPRAM) 2023
The focus of this paper is offline handwriting Stroke Trajectory Recovery (STR), which facilitates the tasks such as handwriting recognition and synthesis. The input is an image of handwritten text, and the output is a stroke trajectory, where each stroke is a sequence of 2D point coordinates. Usually, Dynamic Time Warping (DTW) or Euclidean distance-based loss function is employed to train the STR network. In DTW loss calculation, the predicted and ground-truth stroke sequences are aligned, and their differences are accumulated. The DTW loss penalizes the alignment of far-off points proportional to their distance. As a result, DTW loss incurs a small penalty if the predicted stroke sequence is aligned to the ground truth stroke sequence but includes stray points/artifacts away from ground truth points. To address this issue, we propose to compute a marginal Chamfer distance between the predicted and the ground truth point sets to penalize the stray points more heavily. Our experiments show that the loss penalty incurred by complementing DTW with the marginal Chamfer distance gives better results for learning STR. We also propose an evaluation method for STR cases where ground truth stroke points are unavailable. We digitalize the predicted stroke points by rendering the stroke trajectory as an image and measuring the image similarity between the input handwriting image and the rendered digital image. We further evaluate the readability of recovered strokes. By employing an OCR system, we determine whether the input image and recovered strokes represent the same words.
Strokes Trajectory Recovery for Unconstrained Handwritten Documents with Automatic Evaluation.
Sidra Hanif, Longin Jan Latecki
International Conference on Pattern Recognition Applications and Methods (ICPRAM) 2023
The focus of this paper is offline handwriting Stroke Trajectory Recovery (STR), which facilitates the tasks such as handwriting recognition and synthesis. The input is an image of handwritten text, and the output is a stroke trajectory, where each stroke is a sequence of 2D point coordinates. Usually, Dynamic Time Warping (DTW) or Euclidean distance-based loss function is employed to train the STR network. In DTW loss calculation, the predicted and ground-truth stroke sequences are aligned, and their differences are accumulated. The DTW loss penalizes the alignment of far-off points proportional to their distance. As a result, DTW loss incurs a small penalty if the predicted stroke sequence is aligned to the ground truth stroke sequence but includes stray points/artifacts away from ground truth points. To address this issue, we propose to compute a marginal Chamfer distance between the predicted and the ground truth point sets to penalize the stray points more heavily. Our experiments show that the loss penalty incurred by complementing DTW with the marginal Chamfer distance gives better results for learning STR. We also propose an evaluation method for STR cases where ground truth stroke points are unavailable. We digitalize the predicted stroke points by rendering the stroke trajectory as an image and measuring the image similarity between the input handwriting image and the rendered digital image. We further evaluate the readability of recovered strokes. By employing an OCR system, we determine whether the input image and recovered strokes represent the same words.
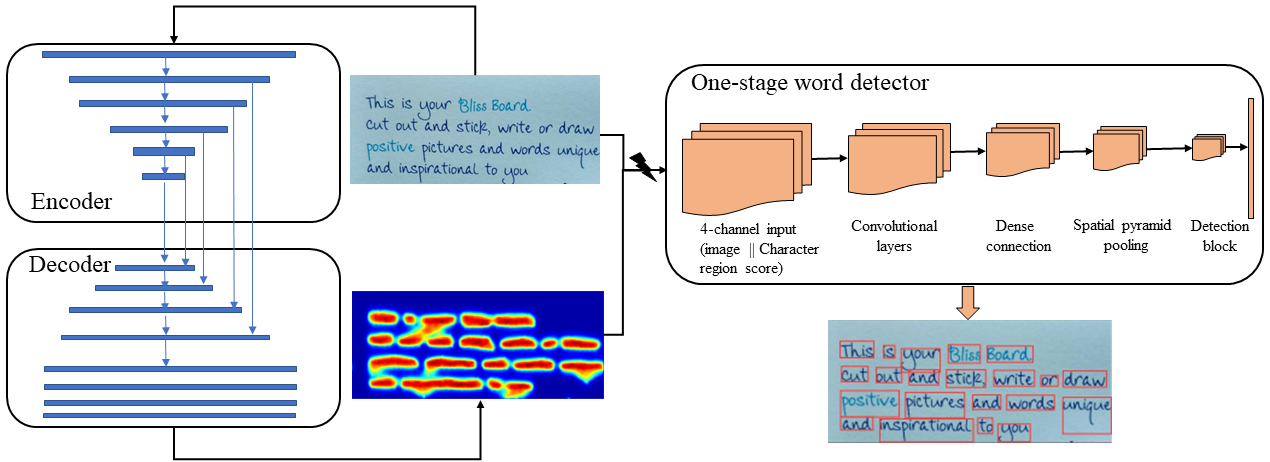
Autonomous Character Region Score Fusion for Word Detection in Camera-captured Handwriting Documents
Sidra Hanif, Longin Jan Latecki
Document Intelligence workshop, ACM SIGKDD 2022
Word detection is considered an object detection problem. However, characters are the basic building block in words, and the presence of characters makes word detection different from general object detection problems. Character region scores identification performs consistently for handwritten text in low-contrast camera-captured images, but detecting words from characters poses a challenge because of variable character spacing in words. Nevertheless, considering the only character and ignoring a word's entirety does not cope with overlapping words in handwriting text. In our work, we propose the fusion of character region scores with word detection. Since the character level annotations are not available for handwritten text, we estimate the character region scores in a weakly supervised manner. Character region scores are estimated autonomously from the word's bounding box estimation to learn the character level information in handwriting. We propose to fuse the character region scores and images to detect words in camera-captured handwriting images.
Autonomous Character Region Score Fusion for Word Detection in Camera-captured Handwriting Documents
Sidra Hanif, Longin Jan Latecki
Document Intelligence workshop, ACM SIGKDD 2022
Word detection is considered an object detection problem. However, characters are the basic building block in words, and the presence of characters makes word detection different from general object detection problems. Character region scores identification performs consistently for handwritten text in low-contrast camera-captured images, but detecting words from characters poses a challenge because of variable character spacing in words. Nevertheless, considering the only character and ignoring a word's entirety does not cope with overlapping words in handwriting text. In our work, we propose the fusion of character region scores with word detection. Since the character level annotations are not available for handwritten text, we estimate the character region scores in a weakly supervised manner. Character region scores are estimated autonomously from the word's bounding box estimation to learn the character level information in handwriting. We propose to fuse the character region scores and images to detect words in camera-captured handwriting images.
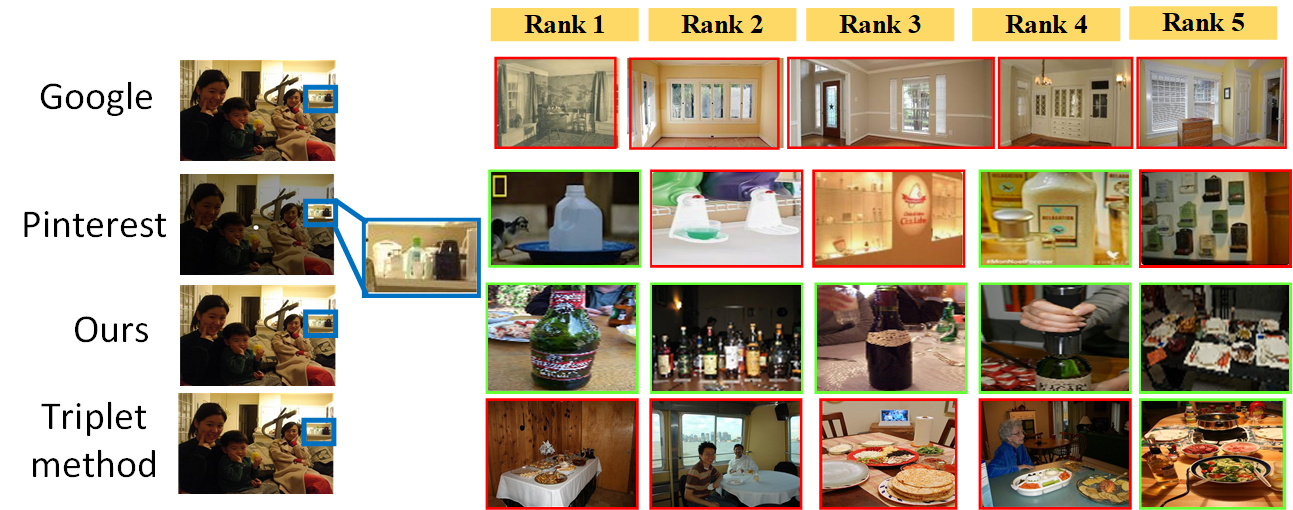
Image retrieval with similar object detection and local similarity to detected objects
Sidra Hanif, Chao Li, Anis Alazzawe, Longin Jan Latecki
Pacific Rim International Conference on Artificial Intelligence 2019
Commercial image search applications like eBay and Pinterest allow users to select the focused area as bounding box over the query images, which improves the retrieval accuracy. The focused area image retrieval strategy motivated our research, but our system has three main advantages over the existing works. (1) Given a query focus area, our approach localizes the most similar region in the database image and only this region is used for computing image similarity. This is done in a unified network whose weights are adjusted both for localization and similarity learning in an end-to-end manner. (2) This is achieved using fewer than five proposals extracted from a saliency map, which speedups the pairwise similarity computation. Usually hundreds or even thousands of proposals are used for localization. (3) For users, our system explains the relevance of the retrieved results by locating the regions in the database images that are the most similar to the query object. Our method achieves significantly better retrieval performance than the off-the-shelf object localization-based retrieval methods and end-to-end trained triplet method with a region proposal network. Our experimental results demonstrate 86% retrieval rate as compared to 73% achieved by the existing methods on PASCAL VOC07 and VOC12 datasets. Extensive experiments are also conducted on the instance retrieval databases Oxford5k and INSTRE, where we exhibit competitive performance. Finally, we provide both quantitative and qualitative results of our retrieval method demonstrating its superiority over commercial image search systems.
Image retrieval with similar object detection and local similarity to detected objects
Sidra Hanif, Chao Li, Anis Alazzawe, Longin Jan Latecki
Pacific Rim International Conference on Artificial Intelligence 2019
Commercial image search applications like eBay and Pinterest allow users to select the focused area as bounding box over the query images, which improves the retrieval accuracy. The focused area image retrieval strategy motivated our research, but our system has three main advantages over the existing works. (1) Given a query focus area, our approach localizes the most similar region in the database image and only this region is used for computing image similarity. This is done in a unified network whose weights are adjusted both for localization and similarity learning in an end-to-end manner. (2) This is achieved using fewer than five proposals extracted from a saliency map, which speedups the pairwise similarity computation. Usually hundreds or even thousands of proposals are used for localization. (3) For users, our system explains the relevance of the retrieved results by locating the regions in the database images that are the most similar to the query object. Our method achieves significantly better retrieval performance than the off-the-shelf object localization-based retrieval methods and end-to-end trained triplet method with a region proposal network. Our experimental results demonstrate 86% retrieval rate as compared to 73% achieved by the existing methods on PASCAL VOC07 and VOC12 datasets. Extensive experiments are also conducted on the instance retrieval databases Oxford5k and INSTRE, where we exhibit competitive performance. Finally, we provide both quantitative and qualitative results of our retrieval method demonstrating its superiority over commercial image search systems.